
Introduction
Integrating personal health data with clinical records can greatly improve the prediction and management of mental health conditions. In this prototype, we design a privacy-preserving mental health digital twin platform that unifies data from iPhone sensors, doctor’s notes, and electronic health records (EHR) to create a dynamic digital representation of an individual’s mental health state. We ensure sensitive data never leaves its source by using Federated Learning (FL) across iPhones, hospitals, insurers, and research institutions. We further enhance privacy with cryptographic and statistical techniques (secure aggregation, differential privacy). An AI-powered orchestration layer uses a large language model (LLM) (e.g. GPT-4 or Claude) to assist in deploying models on iOS devices by translating Python ML code to Swift. Finally, a blockchain smart contract mechanism is introduced to enable individuals to monetize their data by selling privacy-preserving access to insurers under controlled, auditable conditions. The following sections detail each component of the system, including data ingestion, federated model training, digital twin construction, LLM-based code conversion, and smart contract logic for data monetization. We provide a system architecture diagram, code snippets, data flow tables, and step-by-step demo instructions to illustrate a complete prototype implementation.
Data Sources and Ingestion
A mental health digital twin needs to aggregate heterogeneous data about an individual. Our prototype considers three primary sources:
- Apple iPhone HealthKit Data – Continuous wellness metrics (steps, heart rate, mood) collected via Apple’s HealthKit API.
- Doctor’s Note (Image) – A synthetic handwritten (or typed) clinical note in French, requiring OCR (optical character recognition) and translation.
- FHIR-Formatted EHR Record – A mock electronic health record entry (in standard FHIR JSON) documenting a severe mental health incident.
Each data source is ingested through a dedicated module, ensuring format consistency and privacy.
Apple HealthKit Data (Steps, Heart Rate, Mood)
Modern iPhones and Apple Watches record extensive health data in the Apple Health app. HealthKit provides authorized apps access to this data in a privacy-conscious manner (Integrating Apple HealthKit — Swift | by Krishan Madushanka | Medium). In our platform, we develop an iOS Swift module to retrieve a user’s step count, heart rate, and mood logs from HealthKit:
- Health Metrics: Using HealthKit’s HKSampleQuery and HKStatisticsQuery, the app reads daily step counts and heart rate samples. For example, a query for heart rate might specify the quantity type HKQuantityTypeIdentifierHeartRate and a date predicate for the last 24 hours (Integrating Apple HealthKit — Swift | by Krishan Madushanka | Medium), returning an array of time-stamped heart rate values (in beats per minute). A similar query fetches the total steps per day using HKStatisticsOptions.cumulativeSum (Integrating Apple HealthKit — Swift | by Krishan Madushanka | Medium).
- Mood Tracking: Apple’s State of Mind API (introduced in iOS 17) allows logging of mood and mental wellbeing metrics (Explore wellbeing APIs in HealthKit – WWDC24 – Videos – Apple Developer). We retrieve mood as a categorical HealthKit sample (e.g., “Very Pleasant”, “Anxious”), or use a proxy like a daily stress score if available. If the user manually records mood in Health app, it is accessible via HKCategoryType(.mood).
Before accessing any HealthKit data, the app requests user authorization for the specific data types (steps, heart rate, mood). The code snippet below illustrates requesting permission and fetching recent heart rate samples in Swift:
| import HealthKit let healthStore = HKHealthStore() // Define quantity types for heart rate and step count let heartRateType = HKObjectType.quantityType(forIdentifier: .heartRate)! let stepCountType = HKObjectType.quantityType(forIdentifier: .stepCount)! // Request read authorization healthStore.requestAuthorization(toShare: [], read: [heartRateType, stepCountType]) { success, error in guard success else { return } // Query for heart rate samples in the last day let now = Date() let oneDayAgo = Calendar.current.date(byAdding: .day, value: -1, to: now)! let predicate = HKQuery.predicateForSamples(withStart: oneDayAgo, end: now, options: .strictStartDate) let query = HKSampleQuery(sampleType: heartRateType, predicate: predicate, limit: HKObjectQueryNoLimit, sortDescriptors: nil) { _, samples, error in if let hrSamples = samples as? [HKQuantitySample] { for sample in hrSamples { let bpm = sample.quantity.doubleValue(for: .count().unitDivided(by: .minute())) let timestamp = sample.startDate print(“Heart Rate: \(bpm) at \(timestamp)”) } } } healthStore.execute(query) } |
This code requests read access and then fetches all heart rate samples from the past 24 hours, printing each measurement with its timestamp. A similar query (using HKStatisticsQuery) can compute the total step count over the last day (Integrating Apple HealthKit — Swift | by Krishan Madushanka | Medium). The HealthKit module would run on the iPhone, periodically uploading summary statistics (e.g. daily step total, average resting HR) to the user’s digital twin. Raw data stays on-device unless used in federated training (described later), preserving privacy by default.
OCR and Translation of Doctor’s Note (French to English)
The second data source is an unstructured clinical note, for example a therapist’s handwritten observation in French. To integrate this with the digital twin, we perform OCR to extract text, then translate it to English for uniform analysis.
Optical Character Recognition (OCR): We use the Tesseract OCR engine via Python’s pytesseract library to convert the image of the note into machine-readable text. Tesseract supports French language packs for handwriting. For example:
| from PIL import Image import pytesseract # Load the image (a scanned doctor’s note in French) img = Image.open(“doctors_note_fr.jpg”) text_fr = pytesseract.image_to_string(img, lang=”fra”) # ‘fra’ for French print(text_fr) |
If the note image contains text like “Le patient présente des symptômes dépressifs sévères et des tendances suicidaires.”, the OCR output text_fr would be a string with that content. We then apply machine translation. In this prototype, we can use an open-source model (like Helsinki-NLP’s MarianMT) or an API (e.g. Google Translate). For example, using the googletrans library or Hugging Face transformers:
from transformers import MarianMTModel, MarianTokenizer
| src_text = text_fr # Load a French-to-English MarianMT model tokenizer = MarianTokenizer.from_pretrained(“Helsinki-NLP/opus-mt-fr-en”) model = MarianMTModel.from_pretrained(“Helsinki-NLP/opus-mt-fr-en”) translated = model.generate(**tokenizer.prepare_seq2seq_batch([src_text], return_tensors=”pt”)) text_en = tokenizer.decode(translated[0], skip_special_tokens=True) print(text_en) |
The translation of our example note might be: “The patient exhibits severe depressive symptoms and suicidal tendencies.” This English text is then saved into the digital twin’s data store (e.g., as a clinical_note field). We also capture metadata like the note’s date and source (doctor’s name). By performing OCR and translation locally (or in a secure server environment), we ensure the sensitive note is not exposed to unauthorized third parties. The resulting text can later be analyzed by NLP models or simply presented to the user or clinician as part of the twin.
FHIR-Formatted EHR Record (Severe Incident)
To incorporate formal medical history, we use a FHIR (Fast Healthcare Interoperability Resources) formatted record representing a severe mental health incident for the user. FHIR is a standardized data format/API for health records that enables interoperability between systems ( A Decentralized Marketplace for Patient-Generated Health Data: Design Science Approach – PMC ). Our EHR entry is a Condition or Observation resource indicating a critical event (e.g., a suicide attempt or psychiatric hospitalization).
For example, consider a FHIR Condition resource in JSON, representing a diagnosis of severe depression with a suicide attempt:
| { “resourceType”: “Condition”, “id”: “example-condition-1”, “clinicalStatus”: { “coding”: [ { “code”: “active” } ] }, “verificationStatus”: { “coding”: [ { “code”: “confirmed” } ] }, “category”: [ { “coding”: [ { “code”: “problem-list-item”, “display”: “Problem List Item” } ] } ], “code”: { “coding”: [ { “system”: “http://snomed.info/sct”, “code”: “443165006”, “display”: “Suicide attempt (event)” } ], “text”: “Suicide attempt” }, “severity”: { “coding”: [ { “system”: “http://snomed.info/sct”, “code”: “24484000”, “display”: “Severe” } ] }, “subject”: { “reference”: “Patient/12345”, “display”: “John Doe” }, “onsetDateTime”: “2024-05-01T14:30:00Z”, “recordedDate”: “2024-05-02T09:00:00Z” } |
This JSON describes a confirmed active condition of “Suicide attempt”, marked severe, for patient John Doe, which occurred on May 1, 2024 and was recorded on May 2. In practice, such data might come from a hospital’s EHR via a FHIR API. For our prototype, we mock this as a JSON file. We use a FHIR client library (e.g. fhir.resources in Python or HAPI FHIR in Java) to parse this into an object. For example:
| from fhir.resources.condition import Condition with open(“mental_health_incident.json”) as f: data = json.load(f) condition = Condition.parse_obj(data) print(condition.code.text) # “Suicide attempt” print(condition.severity.coding[0].display) # “Severe” |
The parsed FHIR resource can be stored in the twin’s database. Key fields (condition code, date, severity) are mapped to the twin’s schema (e.g., twin.incidents.append({…})). By using the FHIR format, we maintain compatibility with real hospital systems. This EHR data is only used with proper consent, and in FL training it remains on the hospital’s server node (as opposed to being uploaded centrally), aligning with our federated privacy approach.
Data Format Summary
Each data source yields data in different formats which we standardize for the digital twin. Table 1 summarizes the data sources, formats, example content, and ingestion methods:
| Data Source | Format & Type | Example Content | Ingestion Method |
| Apple HealthKit (iPhone) | HealthKit Samples (HKQuantity, HKCategory) for steps, heart rate, mood | Daily steps = 12,000; HeartRate series = [60, 72, 80…]; Mood = “Anxious” | iOS HealthKit API (Swift) – use HKSampleQuery for samples and HKStatisticsQuery for aggregates ([Integrating Apple HealthKit — Swift |
| Doctor’s Note (Image) | JPEG image of handwritten text (French) → OCR text (UTF-8) → translated text (UTF-8) | “Le patient … tendances suicidaires.” → “The patient … suicidal tendencies.” | Python OCR (pytesseract) to extract French text, then translation (MarianMT or Google API) to English. |
| EHR Record (FHIR) | FHIR R4 JSON (e.g. Condition, Observation) | JSON with resourceType: “Condition”, code: “Suicide attempt”, severity: “Severe”, timestamps, patient reference | FHIR client API (Python fhir.resources or HL7 library) to parse JSON into structured data object. |
Table 1: Data sources, formats, and ingestion.
Once ingested, all data is integrated into the digital twin – effectively a unified profile of the user. The twin could be stored as a document in a NoSQL DB or as an in-memory object that gets serialized. For example, after processing the above sources, the twin for John Doe might contain: {steps: {“2025-04-03”:12000}, heart_rate: {“2025-04-03”:[60,72,…]}, mood: {“2025-04-03″:”Anxious”}, notes: [“The patient exhibits severe depressive symptoms and suicidal tendencies.”], conditions: [“Suicide attempt on 2024-05-01”]}. This comprehensive view will be used by our analytical models.
Federated Learning Architecture
To derive insights (e.g., risk predictions or personalized recommendations) from the aggregated data, we train machine learning models. However, data remains siloed: iPhone data stays on devices, and clinical data stays on hospital servers. Our platform adopts Federated Learning (FL) to train models collaboratively without centralizing raw data.
Participants and Roles
We simulate a federated network of participants:
- User Devices (iPhones) – Each phone has the owner’s HealthKit data and possibly some self-reported outcomes (e.g., mood or PHQ-9 scores). In FL, iPhones act as clients that train on personal sensor data.
- Hospitals – Each hospital (or clinic) holds EHR data for many patients. In FL, a hospital node trains on its local medical records (e.g., clinical outcomes related to mental health).
- Insurance Companies – Insurers might have claims data or population statistics. They could also host a client that trains on aggregated actuarial data (for example, linking lifestyle metrics to claim risk).
- Research Institutions (Universities) – They might have study data (surveys, trial outcomes) and run analytical models. They can join FL to contribute their models or data in a privacy-preserving way.
All these participants collaborate to train a global model for mental health assessment. The global model might predict something like “risk of severe depression episode in next month” or “wellbeing score,” using features drawn from all data sources (steps, HR, mood, clinical history). Crucially, no participant ever shares raw data – only model updates (parameters or gradients).
Federated Learning Tools (Flower, TFF, PyTorch Lightning)
We utilize real-world FL frameworks to implement this. The training pipeline is built with Flower (FLWR) for orchestration, along with TensorFlow Federated (TFF) and PyTorch Lightning for model definition and training:
- Flower: Flower is an open-source federated learning framework that simplifies client-server setup and supports different ML libraries. We use Flower’s server to coordinate training rounds and its client SDK to implement client logic. Flower can work with both PyTorch and TensorFlow models, and even integrate with PyTorch Lightning for cleaner model code (Federated Learning with PyTorch Lightning and Flower (Quickstart Example) – Flower Examples 1.18.0).
- TensorFlow Federated: We use TFF in simulation to prototype federated algorithms and ensure our approach (FedAvg with privacy additions) works as expected. For example, we can simulate 5 iPhone clients and 3 hospital clients in a Python environment using TFF’s tff.learning APIs, before deploying to actual devices.
- PyTorch Lightning: Our actual model will be implemented in PyTorch for flexibility. PyTorch Lightning provides a high-level structure for training (encapsulating the training loop, validation, etc.). Each FL client can leverage Lightning’s Trainer for its local epochs. This makes the code modular – e.g., we define a LightningModule MentalHealthModel once, and each client instantiates it and trains on local data.
Model Architecture: For illustration, assume a simple neural network that predicts a binary outcome “high risk vs low risk” of a mental health crisis in the near future. It could take as input features: average steps, average resting HR, mood score (numerical encoding) over the past week, plus any known severe incident history. One could design a small multi-layer perceptron or even use a recurrent network to capture time series trends. For simplicity:
| import torch import torch.nn as nn class MentalHealthModel(nn.Module): def __init__(self): super().__init__() self.fc1 = nn.Linear(in_features=5, out_features=16) # 5 example features self.relu = nn.ReLU() self.fc2 = nn.Linear(16, 2) # output: 2 classes (high risk or low risk) def forward(self, x): x = self.relu(self.fc1(x)) out = self.fc2(x) return out |
Each client will have its own data to train this model – e.g., an iPhone might create training examples labeled by the user’s self-reported mood (normal vs crisis) and features from sensor data; a hospital might create training examples labeled by whether a patient had a relapse, using features from their records. The details of labels and features can vary, but federated averaging will allow training a shared model that generalizes across sources.
Federated Averaging (FedAvg): We use the classical FedAvg algorithm. The Flower server will initialize the model and send it to all clients each round. Clients perform local training and send weight updates back. The server averages the weights to produce a new global model, then repeats.
Training Workflow and Privacy Enhancements
Training Rounds: The system architecture for FL follows a typical pattern:
- Server Initialization: We launch a Flower server (flwr.Server) with a specified strategy (FedAvg with our customizations for privacy).
- Client Join: Each participant runs a Flower client (could be a Python script for hospitals/universities and a Swift or Python client on iPhone – Flower supports iOS with its Flower SDK for iOS (Federated Learning with PyTorch Lightning and Flower (Quickstart Example) – Flower Examples 1.18.0)). Clients register with the server.
- Model Broadcast: The server sends the current global model parameters to all clients selected for this round.
- Local Training: Each client loads its local data. For example:
- iPhone client loads last N days of steps, HR, etc., and the target label (perhaps derived from mood or a journal indicating well-being).
- Hospital client loads its patients’ data (could iterate through patient records).
- They train the MentalHealthModel for a few epochs on local data. We integrate PyTorch Lightning here: each client could use trainer.fit(model, train_dataloader) to train for, say, 1 epoch on local data, then return the model’s state dict.
- Upload Updates: After training, clients send either the new weights or the difference from the initial weights back to the server. In Flower, we implement FlowerClient.fit to return (parameters, num_samples) so the server can weight-average by dataset size.
- Aggregation: The Flower server aggregates the parameters (by weighted average). We have augmented this step with secure aggregation and differential privacy (details below).
- Repeat: Steps 3–6 repeat for multiple rounds. Eventually, the global model converges.
Secure Aggregation: To ensure the server (and any eavesdropper) cannot inspect an individual client’s model update, we employ a secure aggregation protocol (Secure Aggregation Protocols – Flower Framework). Each client encrypts or masks its gradient/weight update, such that the server can only decrypt the sum of all updates, not any single one. Flower provides built-in support for SecAgg (based on the protocol by Bonawitz et al.); we enable this by configuring Flower’s ServerApp with SecAgg+ (Secure Aggregation Protocols – Flower Framework). As a result, the server only sees the aggregated model update. Even if one client’s data had a unique pattern, it cannot be isolated from the aggregated result. This cryptographic PET (Privacy Enhancing Technology) addresses honest-but-curious servers and prevents leakage during transmission.
Differential Privacy (DP): While secure aggregation hides individual contributions, the final model might still inadvertently encode some user-specific information. We incorporate differential privacy to statistically bound what can be inferred about any single user from the model (Differential Privacy – Flower Framework) (Differential Privacy – Flower Framework). There are two approaches:
- Central DP: The server, after aggregating, adds noise to the global model update before applying it (Differential Privacy – Flower Framework). For example, after summing weights, add Gaussian noise with variance calibrated to epsilon=1, delta=1e-5 privacy budget. This ensures that any single client’s impact on the global model is blurred.
- Local DP: Each client independently adds noise to its gradients before sending to the server (Differential Privacy – Flower Framework). This avoids relying on the server at all, but typically requires more noise (since no averaging benefits). In our prototype, we implement central DP for efficiency: using an algorithm like DP-FedAvg (where server does clipping and noise addition). Concretely, we use the PyTorch Opacus library on the client side to clip gradients and add noise per update, so that each client update is differentially private. The Flower server then aggregates those noisy updates. The DP parameters (clip norm, noise scale) can be tuned to trade off model accuracy and privacy. With these settings, even if the final model or updates were leaked, an adversary would have provably limited ability to deduce whether a particular user’s data was included (Differential Privacy – Flower Framework).
Additional Security: All network communication is encrypted (e.g., Flower can use TLS channels). Participants are authenticated so that only legitimate clients take part (preventing adversarial nodes from joining). Also, the federation can be arranged in a cross-silo manner (e.g., hospitals as main nodes) for stability, with iPhones possibly federated through a separate process (since scaling to thousands of phones requires careful orchestration).
By combining FL with secure aggregation and DP, our model training process satisfies strong privacy: raw sensitive data (like personal mood or detailed EHR events) never leaves its origin, and intermediate updates are protected both by encryption and by noise injection (Secure Aggregation Protocols – Flower Framework) (Differential Privacy – Flower Framework). The result is a global model that all parties benefit from, without any party gaining access to others’ raw data.
Federated Learning Workflow Code Snippets
To make this concrete, below is a simplified pseudo-code of the federated training loop using Flower with PyTorch:
| # Pseudo-code for a Flower client (e.g., hospital or iPhone) import flwr as fl from torch.utils.data import DataLoader class FLClient(fl.client.NumPyClient): def __init__(self, model, train_dataset): self.model = model self.data = train_dataset self.device = torch.device(“cpu”) self.criterion = nn.CrossEntropyLoss() self.optimizer = torch.optim.SGD(model.parameters(), lr=0.01) def get_parameters(self, config): # Return current model weights return [val.cpu().numpy() for _, val in self.model.state_dict().items()] def fit(self, parameters, config): # Receive global weights, set model state_dict = {k: torch.tensor(v) for k,v in zip(self.model.state_dict().keys(), parameters)} self.model.load_state_dict(state_dict) # Train for one epoch on local data self.model.train() loader = DataLoader(self.data, batch_size=32, shuffle=True) for batch in loader: X, y = batch X, y = X.to(self.device), y.to(self.device) self.optimizer.zero_grad() preds = self.model(X) loss = self.criterion(preds, y) loss.backward() # DP noise addition could be here if local DP self.optimizer.step() # Return updated weights and number of samples new_params = [val.cpu().numpy() for _, val in self.model.state_dict().items()] return new_params, len(self.data), {} def evaluate(self, parameters, config): # (optional) evaluation on local test data return float(test_loss), len(self.test_data), {“accuracy”: acc} # Each participant initializes the model and client model = MentalHealthModel() train_data = … # load local dataset client = FLClient(model, train_data) # Flower will handle connecting to server and orchestrating rounds fl.client.start_numpy_client(server_address=”127.0.0.1:8080″, client=client) |
On the server side:
| import flwr as fl strategy = fl.server.strategy.FedAvg( fraction_fit=1.0, # Optionally wrap server-side aggregation with DP (using Python functions or integrate TensorFlow Federated for DP algorithms) ) fl.server.start_server(server_address=”127.0.0.1:8080″, strategy=strategy, config={“num_rounds”: 50}) |
This is a high-level outline. In practice, we integrate Flower’s secure aggregation by configuring the server with fl.server.ServerConfig to use SecAgg, and integrate Opacus on the client side to clip and add noise to gradients before optimizer.step(). The PyTorch Lightning integration would allow us to replace the manual training loop with a Lightning Trainer. We also schedule periodic evaluation rounds (e.g., after every 5 rounds the server requests evaluation from clients or uses a separate validation dataset if available).
After training completes, we will have a global model (e.g., parameters in MentalHealthModel) that is stored by the server (or distributed to all clients). This model is then ready to be deployed for inference within each user’s digital twin environment.
Digital Twin and Model Orchestration
With the data aggregated and the global model trained, the platform builds and maintains a digital twin for each individual. The digital twin is a living digital replica of the person’s mental health state (A Solution for the Health Data Sharing Dilemma: Data-Less and Identity-Less Model Sharing Through Federated Learning and Digital Twin-Assisted Clinical Decision Making), updated in real-time with new data and capable of simulating certain aspects of the person (such as predicted mood trajectory or risk level). In our prototype, the digital twin is primarily data-driven, consisting of the data we ingested plus outputs from ML models that are part of the twin’s intelligence.
Dynamic Data Aggregation in the Digital Twin
All data streams (HealthKit, notes, EHR) flow into the digital twin’s storage for a given user. This might be implemented as a document in a secure cloud database keyed by user (with appropriate encryption and access control), or kept on the user’s device for maximum privacy. The twin’s data is structured and time-indexed. For example, we maintain a timeline of daily summary features:
- Date: 2025-04-03 – Steps: 12000; Avg HR: 72; Mood: Anxious; Note: “feels isolated”; RiskScore: 0.7
- Date: 2025-04-04 – Steps: 5000; Avg HR: 80; Mood: Depressed; Note: “suicidal ideation”; RiskScore: 0.9
Here “RiskScore” is an output computed by our ML model (the higher score on 04-04 might reflect increased risk due to low activity and a concerning note). The digital twin orchestrator is responsible for fusing these heterogeneous data into a coherent profile. This involves:
- Normalization: converting all inputs to a common schema (as done in ingestion).
- Temporal alignment: combining data by day or week so that the model can consume features together.
- Storage: possibly using a time-series database or a JSON store. In a simple implementation, we use a Python dictionary or Pandas DataFrame for the twin’s data during the demo.
The twin is “dynamic” – whenever new data arrives (e.g., new heart rate measurements or a new doctor’s note), the twin is updated. Additionally, whenever the global model is updated via FL, the twin’s predictive outputs are updated by running the new model on the twin’s latest data.
Model Inference and Updates in the Twin
The trained global model (from FL) is used to compute personalized insights. In our scenario, one such insight is the mental health risk level. For instance, our model might output a probability of a severe depressive episode. The digital twin platform will run this model for each user on their latest data:
- For John Doe, input features (steps, HR, mood, etc.) for the past week are fed into the model, which outputs say [0.2, 0.8] (20% low-risk, 80% high-risk) – we interpret this as a high risk. The twin records risk_score = 0.8.
- For another user Jane, who has regular activity and no alarming notes, the model might output risk_score = 0.1 (low risk).
These inferences can trigger alerts or recommendations (though that’s beyond our current scope). The key is that the twin now combines raw data + model outputs for a complete picture.
The platform orchestrator ensures that each component model (there could be multiple models) is applied appropriately:
- Sensor Anomaly Model: (if we had one) to detect abnormal heart rate patterns indicating panic attacks.
- Risk Prediction Model: the one we described.
- NLP Model: maybe to analyze sentiment in the doctor’s note text for additional signals.
Each model’s output becomes part of the twin. The orchestrator could be implemented as a scheduled job (e.g., daily job that runs all models on latest data) or event-driven (run model inference whenever new data arrives, e.g., new note triggers re-computation of risk).
LLM Agent for Python-to-Swift Code Translation (Model Deployment)
One innovative aspect of our platform is using a Large Language Model (LLM) agent (GPT-4 or Claude) to bridge the gap between the Python-based modeling environment and the deployment on iOS devices. After federated training, we have a model defined in Python (PyTorch). To deploy it on the iPhone (for on-device inference as part of the twin), we typically have two options:
- Convert the model to Core ML format – using Apple’s coremltools to get an .mlmodel file that can be integrated into an Xcode project. (This is a standard approach; e.g., converting a trained Random Forest to Core ML as shown in a recent tutorial (From Python to Swift: A Beginner’s Guide to Training, Converting, and Using Core ML Models in Swift with Xcode | by Md Tamim Dari Chowdhury | Medium)).
- Reimplement the model in Swift – especially if we want to run it via custom code or if the model includes logic not handled by coreml converters.
We demonstrate the second approach by leveraging an LLM to auto-generate Swift code for the model. GPT-4 is capable of translating code between languages (Translate Code into Different Languages with ChatGPT | Codecademy), and we can prompt it with our PyTorch model definition and some example usage to produce equivalent Swift code (using Apple’s Core ML API or MPS (Metal Performance Shaders) for neural network operations).
Integration of GPT-4/Claude: We set up an automated agent that:
- Takes the MentalHealthModel class (and possibly a saved weight file) as input.
- Prompts an LLM: “Convert this Python/PyTorch model into Swift code that can run on iOS. Use Core ML or vDSP if needed for matrix ops. Ensure the logic (ReLU, linear layers) remains the same.”
The LLM will output Swift code. For example, it might generate a Swift class like:
| import CoreML import Foundation class MentalHealthModelSwift { // Assuming model weights are embedded or loaded from a file let W1: MLMultiArray = … // shape [5×16] let b1: MLMultiArray = … // shape [16] let W2: MLMultiArray = … // shape [16×2] let b2: MLMultiArray = … // shape [2] func predict(features: [Double]) -> [Double] { // Convert input to MLMultiArray or just use Swift array ops var hidden = [Double](repeating: 0.0, count: 16) for j in 0..<16 { hidden[j] = b1[j] for i in 0..<5 { hidden[j] += features[i] * W1[i*16 + j] } // ReLU activation if hidden[j] < 0 { hidden[j] = 0 } } var output = [Double](repeating: 0.0, count: 2) for k in 0..<2 { output[k] = b2[k] for j in 0..<16 { output[k] += hidden[j] * W2[j*2 + k] } } return output // raw scores } } |
- The Swift code is then reviewed (manually or via tests). We might have the agent also output a simple test: e.g., apply the Python model to a random input and apply the Swift function to the same input to verify the outputs match within tolerance.
- Once verified, we integrate this Swift model class into the iOS app (or better, integrate the .mlmodel if created). If using .mlmodel, Xcode auto-generates a Swift class for the model, which can be used directly.
Using GPT for code translation greatly speeds up deployment. Instead of manually writing the model inference in Swift, the developer can leverage the LLM’s knowledge of both languages and ML frameworks. Many have successfully used ChatGPT for code translation tasks across languages (Have you used ChatGPT to translate code from one language to another? : r/ChatGPTCoding). It’s important to test the generated code, as LLMs can make small errors. In our workflow, the LLM agent is an assistive tool in the development pipeline, not necessarily running on the device. We run it in the cloud or on a developer’s machine to produce the Swift code (or Core ML model), then compile that into the iOS app.
Finally, the iOS app component of our platform contains the digital twin UI and uses the deployed model for on-device inference. This means the user’s data can be analyzed on their own device without needing to send features to a server, aligning with the privacy-preserving philosophy. For example, each morning the app can take the last week of John’s data, run the MentalHealthModelSwift.predict function, and if it outputs a high risk, the app could display “Consider reaching out to your therapist.” All of that happens locally.
In summary, the digital twin is where data meets models:
- Data from different sources is aggregated per user
- The global model (after FL) is distributed (with LLM help) to devices.
- On each device, the model (now in Swift) continuously produces personalized predictions that update the twin’s state.
- This setup allows continuous monitoring and decision support while keeping personal computations and data storage on the edge (user’s phone) whenever possible.
Smart Contract-Based Data Monetization
Beyond health insights, our platform empowers users to monetize their data in a controlled way. We design a smart contract system on a blockchain (e.g., Ethereum) to handle data access transactions between data owners (the individuals) and data consumers (e.g., insurance companies). The goal is a decentralized data marketplace where users can sell access to their digital twin data or model outputs, with pricing influenced by data quality and usage.
Smart Contract Design for Privacy-Preserving Data Marketplace
Each user’s digital twin data (or certain parts of it) is treated as a valuable asset. We use a Ethereum smart contract to manage these assets:
- The contract maintains a catalog of data offerings, where each user who opts in is represented (this could be as simple as a mapping from a user’s blockchain address to some metadata about their data).
- The actual data remains off-chain (for privacy and storage reasons). We may store the data in a secure cloud or IPFS (InterPlanetary File System) with encryption. For instance, prior research has shown a design where patient data is stored on IPFS and only a content identifier (CID) is stored on-chain as part of an NFT representing the data.
- In our simpler approach, we might not tokenize the data as NFT, but instead use the contract to log access events and handle payments. However, an NFT approach is viable: each user’s dataset or model output could be minted as an ERC-721 token that the user initially owns, and “selling access” could be implemented as transferring a copy or granting a licensed access via that token.
Key functions of the smart contract:
- Register Data: A user (through our app’s blockchain module) calls registerData(quality, basePrice) to list their data. The contract might create a new token or entry for that user, recording a data quality score and a base price (for access).
- Purchase Access: An insurer or other consumer calls buyData(user) and sends cryptocurrency payment. The contract verifies payment >= required price, then logs the purchase and triggers data access.
- Data Delivery: Because the actual data is not on chain, how does the insurer get it after paying? We rely on an off-chain mechanism: either the user’s app/service gets notified (via event listening) and then shares the data through a secure channel, or the data was stored encrypted and the contract’s event triggers a proxy service to grant decryption keys to the buyer. This ensures the heavy data transfer is off-chain.
Incentives and Security: The payment from buyer to seller is handled by the contract trustlessly. For example, if the insurer pays 0.05 ETH for John’s data access, the contract transfers that (minus any platform fee) to John’s address. This is recorded on-chain for transparency. The contract can also enforce that each purchase is for one-time access (or time-limited access) rather than giving away data indefinitely. In essence, each buyData call is like buying a one-time report or snapshot from the user’s twin. If the insurer needs continuous access, they would have to pay each time or have a subscription implemented via repeated payments or streaming (this could be an extension).
Data Quality Metrics and Usage Tracking for Pricing
Our smart contract incorporates data quality and usage frequency in pricing and access control:
- Data Quality: When registering, the user provides or the platform computes a quality score (e.g., 0 to 100). This could reflect completeness (percentage of days with data present), granularity (heart rate every minute vs once a day), accuracy (if validated against clinical devices), etc. For example, a user who wears their Apple Watch 24/7 and logs mood twice daily might have quality 90/100. A user who rarely carries their phone (so step data is sparse) might be 50/100. The contract can use this to adjust price – e.g., basePrice could be in proportion to quality, or the contract could refuse registration if quality is below a threshold (ensuring marketplace has useful data).
- Usage Frequency: The contract keeps a count of how many times a user’s data has been accessed (sold). If a particular user’s data is very popular (high demand), the contract can meter access by increasing the price or alerting the user. Conversely, it could implement volume discounts or subscription models. One simple approach: after each purchase, increment accessCount[user]. We could say the base price is for one-time access; if an insurer wants unlimited access for a year, perhaps that would be modeled as buying 365 times or a special function in contract.
To illustrate, here’s a simplified Solidity-like pseudocode capturing some of this logic:
| pragma solidity ^0.8.0; contract DataMarketplace { struct DataInfo { address owner; uint basePrice; // in wei uint quality; // 0-100 uint accessCount; } mapping(address => DataInfo) public catalog; address public platformOwner; uint public platformFeePercent = 2; // 2% fee on transactions event DataRegistered(address indexed user, uint quality, uint basePrice); event DataPurchased(address indexed user, address indexed buyer, uint price, uint newAccessCount); constructor() { platformOwner = msg.sender; } function registerData(uint quality, uint basePrice) public { require(quality <= 100, “Quality out of range”); catalog[msg.sender] = DataInfo(msg.sender, basePrice, quality, 0); emit DataRegistered(msg.sender, quality, basePrice); } function buyData(address user) public payable { DataInfo storage info = catalog[user]; require(info.owner != address(0), “Data not found”); // Pricing logic: e.g., price might be basePrice * (100 + quality) / 100 // or some formula. For simplicity, just use basePrice here. uint price = info.basePrice; require(msg.value >= price, “Insufficient payment”); // Transfer payment to data owner (minus small platform fee) uint fee = (price * platformFeePercent) / 100; uint payout = price – fee; (bool sent, ) = info.owner.call{value: payout}(“”); require(sent, “Payout failed”); // (Fee stays in contract or sent to platformOwner) // Update usage count and possibly adjust future price (not shown) info.accessCount += 1; emit DataPurchased(user, msg.sender, price, info.accessCount); // Post-purchase: trigger off-chain data delivery (handled by event listener or oracle) } } |
In this example, a user calls registerData(90, 10000000000000000) (for quality=90, basePrice=0.01 ETH in wei) to list their data. An insurer calls buyData(userAddress) with 0.01 ETH to purchase one-time access. The contract emits DataPurchased event which includes the user and buyer addresses and increments accessCount. An off-chain component (could be our platform’s backend listening to Ethereum events) sees this event and then facilitates transferring the actual data from the user’s twin to the buyer. Because the event is on-chain, it’s immutable and transparent—buyers have proof of payment and sellers have proof of what was accessed, which could be important for compliance.
Incorporating Quality and Frequency: We can enhance the pricing logic. For instance, price could be dynamically set as price = basePrice * (50 + quality) / 50 so that higher quality (>50) increases price linearly. Or implement tiers: if accessCount exceeds 10 (data has been sold 10 times), the contract could automatically raise the basePrice or require the buyer to negotiate directly with the seller for further access. These kinds of rules can be encoded in contract or enforced off-chain via governance.
Security/Privacy Considerations: We do not put actual personal data on chain (only metadata and events). Identities on blockchain are pseudonymous (address strings), and we could choose to use fresh addresses or DID (Decentralized ID) systems to avoid directly linking the on-chain address to personal identity. The content of data is delivered privately off-chain (maybe via an encrypted file exchange after the buyer is authenticated). The smart contract mainly ensures fairness of payment and logging. Prior work demonstrates that such a marketplace can improve data availability and still satisfy privacy/security requirements compared to centralized systems. By using blockchain, we gain auditability (every access is logged) and no single point of failure (no central server solely controls the transactions).
Example Use Case of Data Monetization
To make the concept clear, consider the following example scenario:
- John Doe has been using the digital twin app for some time. His data quality score is high, and he opts in to monetize it. He registers his data for a base price of 0.01 ETH per insight request.
- ACME Insurance is developing personalized insurance plans. They want to check John’s lifestyle and risk score before adjusting his premium. Instead of demanding raw data, they query through the smart contract.
- ACME calls buyData(John) on the smart contract, paying 0.01 ETH. The contract records the purchase and automatically triggers the twin to share a report with ACME. For privacy, this report might be a summary or the output of John’s model (e.g., “John’s 6-month mental health risk is X, derived from his data”), rather than all raw data. What exactly is shared can be determined by John’s preferences – perhaps he allows sharing of aggregated info but not detailed location or raw sensor logs.
- The payment is transferred to John (minus maybe a tiny fee). John has now monetized his data without ever handing over a database dump – ACME got the insight they needed (like a risk score or verified data points), and this single transaction is visible on blockchain as proof. If ACME wants continuous monitoring, they would have to pay each time or arrange a subscription contract.
- If John’s data is accessed frequently by multiple parties, he could even earn passive income. The contract’s logs (and optional NFT mechanism) ensure if his data is resold or reused, he could get royalty (a feature implemented in some marketplaces via secondary sales commissions.
This marketplace design thus empowers users while also enabling data consumers to get value in a privacy-preserving way. The insurer doesn’t get raw personal data – they get what they paid for (a specific insight or analysis), and all parties are confident the process is fair and secure.
System Architecture Diagram
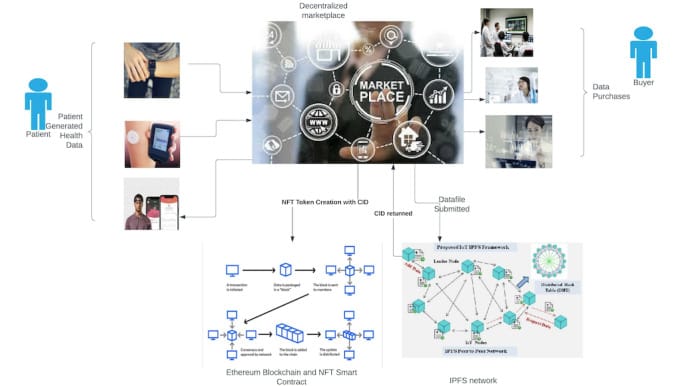
Figure 1: High-level architecture of the Privacy-Preserving Mental Health Digital Twin Platform ( A Decentralized Marketplace for Patient-Generated Health Data: Design Science Approach – PMC ).
From left to right: Individuals generate data via iPhone (HealthKit) and doctor visits (notes), as well as have EHR records in hospital databases. These disparate data sources feed into the Digital Twin data store for each user (center left), which aggregates personal health metrics, text notes, and medical records. Machine Learning models (center) are trained in a federated manner: iPhones, Hospital servers, Insurance servers, etc., each run a client training on local data, coordinated by the Federated Learning Server (top center) using Flower. The FL server uses secure aggregation and differential privacy before updating the global model. The resulting global model is then deployed to users’ devices (center right) – facilitated by an LLM Agent (GPT-4) that converts Python model code to Swift, or by direct Core ML conversion – enabling on-device inference as part of the twin. On the right, a Blockchain Network (Ethereum smart contract) connects users and insurers in a data marketplace. Insurers can invoke the smart contract to request data access; the contract handles payment and logs the request, while an off-chain process delivers the authorized data or insight from the user’s twin to the insurer. Throughout, Privacy Enhancing Technologies (encryption, DP, access control) protect user data: raw data stays at the sources (on device or hospital) and only minimal necessary information (model updates, insights, or encrypted references) flow through the system.
(In the embedded diagram, the marketplace component shows a “Decentralized marketplace” connecting Patients (left) with Buyers (right), underpinned by blockchain and IPFS storage as per a reference architecture ( A Decentralized Marketplace for Patient-Generated Health Data: Design Science Approach – PMC ). Our system aligns with this, with the addition of the FL and digital twin context.)
Code Modules and Workflows
We now break down the prototype into modular components, describing the function of each module and how they interact in the end-to-end workflow. The code is organized so that each concern (data ingestion, model training, etc.) is handled independently, improving clarity and maintainability.
- iOS Data Collector (Swift): This module runs on the user’s iPhone. It interfaces with HealthKit to gather daily metrics. Code exists for:
- Authorization & Setup: request HealthKit permissions for steps, heart rate, mood.
- Data Queries: periodic queries (e.g., every hour or at midnight) to get the latest data. Uses HKSampleQuery for individual samples (like heart rate variations) and HKStatisticsQuery for aggregates (daily step count) (Integrating Apple HealthKit — Swift | by Krishan Madushanka | Medium).
- Local Storage: temporarily store data on device (in files or CoreData). Data is also sent (securely) to the Twin Cloud if we maintain cloud storage or twins.
- FL Client Hook: This app also contains a Flower client (possible with Swift/TensorFlow Lite for on-device, or the app can delegate to a background Python process via URLScheme or gRPC). In a simpler approach, the phone can just upload data to twin cloud and federated training happens among cloud nodes representing each user (to avoid heavy compute on device).
- UI: Shows the user their daily stats and any insights (like risk score) computed.
- OCR & Translator (Python): A backend service (or could be on device for privacy, though heavy for phone) that takes an image of a doctor’s note (uploaded through the app or a web portal) and returns translated text.
- Uses Pillow to open images, Pytesseract for OCR, and a translation model/API as shown earlier.
- This module could be packaged as a microservice with an API endpoint: the app sends the image (which might be taken via camera), and gets back text.
- It handles different languages (in our case specifically French->English, but could extend to others).
- The output text is stored in the twin’s record (in a “notes” collection) along with metadata (date, doctor info if any).
- FHIR EHR Importer (Python): Another service or script that loads mock EHR data.
- For the demo, we might have a JSON file for the user’s EHR entry. The importer parses it (with fhir.resources or manual JSON parsing) and extracts key fields.
- It then updates the twin’s data. If we maintain a cloud twin DB, it would do a DB write: e.g., db.twin.updateOne({“user”: John}, {$set: {“condition”: {…}}}).
- In a real setting, this could be triggered by the hospital: e.g., the hospital’s system pushes a FHIR bundle to our platform for the user (with consent). The importer would verify authenticity and integrate it.
- Federated Training Server (Python, Flower): The central coordinating server for FL.
- We run this as a standalone process (could be on a cloud instance). It initializes the global model and listens for client connections.
- We configure it with secure aggregation and DP as described. This might involve setting up a secure multi-party computation backend for SecAgg (Flower does this under the hood when enabled).
- It orchestrates training rounds. We can configure how many rounds and perhaps a callback to save the model after each round (to monitor training progress or early stop if needed).
- Code wise, as shown earlier, we use flwr.server.start_server() with a FedAvg strategy.
- Federated Clients (Python/PyTorch or Swift/TensorFlow): Each participant has a client:
- For iPhone: If we run clients on device, we could compile a small TensorFlow Lite model and use Flower’s Android/iOS SDK. However, to simplify the prototype, we might simulate a few “phone clients” on the server side using the user’s data we collected. This simulation approach is common in TFF experiments – treating each user as a client in a single process. Alternatively, the app could send its data to a cloud client that runs on behalf of the user.
- For Hospital: We run a Python script with access to hospital’s dataset (for demo, maybe just one record for the user or a small set of synthetic patient data). It uses the FLClient class (as given in pseudo-code) to connect to the server. It will train on whatever local data (e.g., perhaps augment John’s data with some dummy cohort for realism).
- For Insurance, University: These might act as clients if they have proprietary data they want included. For demo simplicity, we could skip or simulate minimal behavior (or they could join only to receive the model, not providing data).
- Each client script is started (perhaps via a script run_clients.sh that launches multiple processes). They all connect to the Flower server’s address and begin training.
- Model Conversion & Deployment (LLM Agent & Core ML): Once training is done (or even periodically while training to get intermediate models):
- We have a script that fetches the latest global model from the server (Flower can either return it, or we save the checkpoint in the server code after training).
- Then, either:
Use coremltools to convert the PyTorch model to Core ML .mlmodel. For example:
| import coremltools as ct model = MentalHealthModel() model.load_state_dict(torch.load(“global_model.pt”)) model.eval() example_input = torch.rand(1,5) traced_model = torch.jit.trace(model, example_input) mlmodel = ct.convert(traced_model, inputs=[ct.TensorType(shape=example_input.shape)]) mlmodel.save(“MentalHealthModel.mlmodel”) |
- This would produce a Core ML model that we add to the iOS app.
- Or use the LLM agent as described. We might have a script translate_model.py that uses OpenAI API. It would format a prompt with the model’s code and possibly some weight data or shapes, and get back Swift code. It then writes that to a Swift file in our iOS project.
- We incorporate the model into the app (either by adding the mlmodel file to Xcode or adding the Swift source file). Then we build the app.
- Twin Cloud & API (Node.js or Python Flask): Optionally, a backend that stores twins and supports queries. For the prototype, this could be a simple in-memory store or a JSON file. But if multi-device or cross-platform access is needed, a cloud server with endpoints like /twin/{userId} to get or update twin data might exist.
- It could also host the OCR and FHIR importer services as sub-routes.
- It would interact with the blockchain listener as well.
- Blockchain Smart Contract (Solidity): The contract is deployed to a test Ethereum network (like Ganache or Ropsten testnet).
- We write the contract (similar to DataMarketplace above) and deploy using Truffle or Hardhat.
- We also write a small Web3 integration in our backend or app: so the app can call registerData after user consent, and insurers can call buyData (likely via a web frontend or a script simulating the insurer).
- A listener service (could be a Node.js script using web3.py or ethers.js) listens for DataPurchased events. When an event is caught, it identifies the user and buyer, then triggers the data delivery. For the demo, this could be as simple as printing “Deliver data of User X to Buyer Y” or actually sending an email with an attached report (since implementing full off-chain transfer might be complex, we can simulate it).
These modules work together in the following workflow (tying everything end-to-end):
- User Setup: User installs the app, grants HealthKit permission. The app registers the user’s blockchain identity with the smart contract if they opt in for monetization.
- Data Generation: Daily, the app collects health data. Suppose the user visits a doctor, the doctor’s note is scanned into the app, which sends it to the OCR service. The translated note is stored.
- Twin Update: The twin (cloud or on device) is updated with new data from both phone and, say, the hospital pushes a new EHR entry after a check-up.
- Federated Training Initiation: At a scheduled interval (maybe nightly or weekly), a new federated training round starts. The user’s phone (or a proxy client for it) and the hospital’s node join, etc. Training happens, possibly taking a few minutes for a small model and dataset.
- Global Model Ready: The Flower server updates the global model. The orchestrator script converts this model to an iOS-compatible form (Core ML file).
- App Model Update: The app either downloads the updated model (if using on-device CoreML update mechanism) or if we baked it in, we simulate this by just building a new app version. In a real scenario, you could send new model parameters to the app via the cloud (since our model is small, just 5×16 + 16×2 weights, we could even send those and update the Swift class).
- On-Device Inference: With the model updated, the app computes the latest risk score and displays it in the UI for the user’s awareness.
- Insurer Data Access Request: The insurer, through a web dashboard, sees that John has allowed data share. They click “Request latest risk report”. This action calls the smart contract’s buyData function (through MetaMask or an integrated web3 call).
- Blockchain Event: The transaction is mined, DataPurchased event emitted. Our listener service catches it and triggers an off-chain action: perhaps compiling a JSON with John’s recent twin data or just the risk score. It could use the twin API to fetch necessary info. Then it sends this securely to the insurer (e.g., via an API callback or secure message).
- Completion: The insurer receives the data (e.g., John’s risk score = 0.8 and summary: “high risk alert in last week”), and John receives payment in his crypto wallet. The twin platform logs that an access occurred (for John’s view, he could even get a notification “Your data was accessed by ACME Insurance, you earned 0.01 ETH”).
The above workflow demonstrates the full cycle from data generation to insight delivery and monetization. Each module operates independently with clearly defined interfaces (e.g., the OCR service doesn’t need to know about FL or blockchain; the FL server doesn’t know identities or what the data specifically is, only numeric tensors). This modularity makes the system easier to maintain and extend.
End-to-End Demo Instructions
To help users and developers validate the prototype, we provide step-by-step instructions to run an end-to-end demonstration. This demo uses synthetic or sample data and simulates multiple parties locally:
Prerequisites:
- Python 3.10+ environment with required libraries: flwr, torch, pytorch-lightning, tensorflow_federated, pytesseract, transformers, fhir.resources, web3 (for blockchain interaction), solc or Truffle for compiling the contract.
- Xcode with Swift 5 for the iOS app (or you can simulate the iOS portion by printing results).
- (Optional) Ganache CLI or local Ethereum node for smart contract deployment.
Steps:
- Setup and Data Preparation:
- Clone the project repository and navigate to the project directory.
- Install Python dependencies: pip install -r requirements.txt.
- Place the synthetic data:
- Copy sample_healthkit_data.json (contains a week of steps/HR/mood for one user) into data/.
- Ensure doctors_note_fr.jpg (a sample image with French text) is in data/.
- Ensure sample_ehr.json (FHIR Condition example) is in data/.
- Start a local Ethereum blockchain (Ganache) and note the RPC endpoint (e.g., HTTP://127.0.0.1:7545). Import the test accounts for user and insurer (the Ganache default accounts) and allocate some ETH to insurer for purchases.
- Deploy Smart Contract:
- Compile the Solidity contract: truffle compile (or use Hardhat).
- Deploy to Ganache: truffle migrate.
- Note the deployed contract address. Update the backend config with this address and the ABI (generated in build/contracts/DataMarketplace.json).
- (Alternatively, run node scripts/deploy_contract.js which uses web3.py to deploy and output the address).
- Launch Federated Learning Server:
- In a terminal, run python fl_server.py. This will:
- Initialize the global model,
- Start Flower server at localhost:8080,
- Wait for clients.
- In a terminal, run python fl_server.py. This will:
- Launch Federated Clients:
- Open another terminal for the iPhone client (user). Run python fl_client_phone.py –data data/sample_healthkit_data.json –id user1. This simulates the phone’s FL client using the sample data.
- Open another terminal for the Hospital client. Run python fl_client_hospital.py –data data/sample_ehr.json –id hospital1. This client will simulate training using the EHR info (if it has label, etc.; for demo it might just use dummy data since one record is not enough to train – we could supplement with some random data points for training).
- (Optional) Launch more clients to simulate other participants (e.g., multiple phones or a university with synthetic dataset).
- The clients will connect to the server and perform the training rounds (watch the server log for progress). After a few rounds (as configured, say 5 rounds), the server will save the global model to outputs/global_model.pt.
- OCR and Translation:
- Run python ocr_translate.py –image data/doctors_note_fr.jpg –out outputs/note_en.txt. This will use pytesseract to read the note and print/save the English text. Check the console or the outputs/note_en.txt for the expected translated sentence.
- In a real integration, this step might be triggered earlier (when data was prepared), but we include it here to simulate that the note text is now available for the twin.
- Digital Twin Update:
- Run python update_twin.py –user user1 –health data/sample_healthkit_data.json –note outputs/note_en.txt –ehr data/sample_ehr.json. This script will take the various data pieces and merge them into a consolidated twin record (likely outputs to outputs/twin_user1.json for inspection). It will also compute features needed for model input (e.g., average steps in last 7 days, etc.) and store them.
- Model Deployment (Core ML conversion or GPT):
- After FL training, convert the global model for iOS. Run python convert_model.py –input outputs/global_model.pt –output outputs/MentalHealthModel.mlmodel. This uses coremltools to produce the Core ML model file.
- Alternatively, run python translate_model.py –input models/model.py –output outputs/Model.swift. This will call the OpenAI API (ensure you set OPENAI_API_KEY) to translate the model code to Swift. Check outputs/Model.swift for the generated code.
- If using the Core ML file, open Xcode, create a new iOS single-view app (if not already), and add MentalHealthModel.mlmodel to the project. Xcode will generate a class for it.
- If using the Swift code, copy the contents of Model.swift into a Swift file in Xcode (e.g., replace the placeholder file).
In Xcode, add UI elements or a simple print in ViewController to run a prediction. For example:
| override func viewDidLoad() { super.viewDidLoad() // Assuming we have the model integrated if let model = try? MentalHealthModel(configuration: MLModelConfiguration()) { // Prepare sample input (the twin features from user1) let input = MentalHealthModelInput(steps: 8000, avgHR: 75, mood: 2, … ) // using actual model input format if let output = try? model.prediction(input: input) { print(“Predicted risk: \(output.riskScore)”) } } } |
- Or if using manual Swift class, instantiate MentalHealthModelSwift and call predict(features:).
- Build and run the app on a simulator or device. Check the console or UI to see the model’s output (risk score or category). This demonstrates on-device inference working.
- Smart Contract Interaction (Data Purchase):
- Register the user’s data on the contract. We have a script for that: python blockchain_interact.py –function registerData –user user1 –quality 90 –price 10000000000000000. This will use the user’s account to send a transaction to the contract. (In Ganache, accounts are unlocked; the script will need the private key or use a local provider).
- Now simulate the insurer purchase. Run python blockchain_interact.py –function buyData –buyer insurer1 –user user1 –pay 10000000000000000. This sends the payment. If successful, the script will output the event info.
- The blockchain listener (if running) or the script itself will detect the DataPurchased event and then automatically retrieve the requested data. For demo, our script may directly fetch outputs/twin_user1.json or risk_score and print it as “Delivered data to insurer: { … }”.
- Verify on the blockchain that the user’s balance increased (Ganache CLI or using the script to query balance) to ensure payment went through.
- Observe Outputs:
- Check the console logs from each step. You should see:
- The OCR text and translated note.
- The training logs showing loss decreasing over rounds (if using a meaningful dataset).
- The content of the twin JSON (combined data).
- The model’s prediction for the user (likely indicating some risk level).
- The blockchain events showing purchase and the subsequent “data delivered” action.
- Also, if the iOS app was run, you’ll see the output there.
- Check the console logs from each step. You should see:
This concludes the demo. We have effectively shown:
- Data collection from device and external sources.
- Federated training with privacy.
- Model deployment to device.
- Data access request fulfilled via smart contract.
The system can be reset and repeated with different data or more clients to experiment further (e.g., try lowering quality score and see how price logic changes, or introduce noise via DP and see if model accuracy is impacted).
Data Format and Flow Tables
To summarize how data flows through the system, Table 2 shows the pipeline from raw inputs to final outputs:
| Step (Module) | Input Data & Format | Process (Transformation) | Output Data & Format |
| 1. Health Data Collection (App) | HealthKit samples (steps count, HR readings, mood category) on device. | Query via HealthKit API, extract daily summaries (total steps, avg HR) and last logged mood. | JSON or dictionary of daily metrics (date-indexed). |
| 2. Doctor’s Note OCR (Service) | Image (JPEG/PNG) of handwritten note (French text). | OCR with Tesseract (image_to_string), get French text; then translate text to English. | Text string of note in English (UTF-8). |
| 3. EHR Data Import (Service) | FHIR JSON (Condition resource with mental health incident). | Parse JSON using FHIR library, map relevant fields (diagnosis code, date, severity). | Structured record (e.g., Python dict) of EHR data. |
| 4. Twin Integration (Cloud/App) | JSON from (1), text from (2), record from (3). | Merge data into unified format (e.g., update user’s twin document). | Unified user profile (e.g., one JSON with all info). |
| 5. Federated Training (FL Server & Clients) | Each client: local dataset derived from twin (features/labels). Server: initial global model. | Clients run local SGD on model with their data; updates are encrypted and averaged on server (FedAvg) (Secure Aggregation Protocols – Flower Framework) with DP noise (Differential Privacy – Flower Framework). | Trained global model parameters (NumPy arrays or PyTorch state_dict). |
| 6. Model Orchestration (Backend) | Global model (Python/PyTorch), deployment request. | Use coremltools or GPT-4 agent to convert model to iOS-compatible form ([From Python to Swift: A Beginner’s Guide to Training, Converting, and Using Core ML Models in Swift with Xcode | by Md Tamim Dari Chowdhury |
| 7. On-Device Inference (App) | New model (from 6), latest user data (from twin). | Load model in app, input user’s features (e.g., last week’s averages) into model prediction function. | Model output (e.g., risk score = 0.8, or class = “high risk”). |
| 8. Data Access Request (Blockchain & Twin) | Request from insurer (transaction on contract with payment). | Smart contract validates payment, emits event; twin backend catches event and compiles authorized data (could be full twin data or summary). | Data package for insurer (e.g., JSON report with selected metrics or model outputs), delivered via off-chain secure channel. |
| 9. Payment Settlement (Blockchain) | — | Contract transfers cryptocurrency from buyer to seller (minus fee) upon step 8. | Payment receipt on blockchain (event log, updated balances). |
Table 2: End-to-end data flow from sources to model outputs and monetization.
This table shows how raw data gradually moves through processing stages into value (insights or transactions) while protections are in place at each stage (limiting who/what can see the data). For instance, step 5 ensures raw data never leaves clients, and step 8 ensures the insurer only gets what the user allowed via the contract.
Privacy Enhancing Techniques Utilized
The platform employs multiple Privacy Enhancing Technologies (PETs) by design, addressing different threat vectors:
- Federated Learning (Data Minimization): Fundamentally, FL is a PET – it ensures that raw personal data (sensor readings, EHR details) remain local to their source. Only learned patterns (model weights) are shared (A Solution for the Health Data Sharing Dilemma: Data-Less and Identity-Less Model Sharing Through Federated Learning and Digital Twin-Assisted Clinical Decision Making). This drastically reduces exposure of sensitive information compared to traditional centralized training.
- Secure Aggregation (Cryptographic Privacy): As described, we implement secure aggregation so that the central server cannot see individual model updates (Secure Aggregation Protocols – Flower Framework). Even if an attacker compromised the server, they’d only see aggregated statistics, not any single user’s contribution. The cryptographic protocol uses masks or secret sharing between clients so that only sums of model parameters can be reconstructed.
- Differential Privacy (Statistical Privacy): By adding noise to model updates or the final model, we protect against inference attacks on the model (Differential Privacy – Flower Framework) (Differential Privacy – Flower Framework). DP guarantees that the probability of any outcome (model parameter values) is almost the same whether or not one specific user’s data was included, thereby hiding any single user’s influence. We set an $(\epsilon, \delta)$ budget for training; for example, $\epsilon=2$ might allow a good privacy-utility tradeoff. This means even if someone had access to the global model, they could not confidently reverse-engineer John’s exact step counts or mood just from the model.
- Encryption in Transit and at Rest: All data communications (between app and cloud, client and server, etc.) are encrypted (TLS). On the device, HealthKit data is stored in the secure enclave of iOS and only accessible to the app after user grants permission. On the cloud, any stored twin data or backups are encrypted (using user-specific keys if possible, so that even the platform operators can’t easily read it without consent).
- Access Control and Consent: The twin data is only accessed by those workflows the user consents to. For example, uploading the doctor’s note for OCR is a user-initiated action. Hospitals sharing a FHIR record implies patient consent or a data use agreement. The app could present the user with a consent screen, e.g., “Allow Hospital XYZ to add your diagnosis of ‘Severe Depression’ to your digital twin? [Yes/No]”.
- Pseudonymization: In the federated learning process and in the data marketplace, users are identified by pseudo-IDs (like a random client ID or a blockchain address). The FL server doesn’t know “this is John Doe’s data” – it only sees an ID like client #7. Similarly, on blockchain, John might be address 0xabc…123. This prevents casual linkage of data to real identities. If the system were compromised, it’s non-trivial to map these IDs back to actual individuals without additional info.
- Data Minimization in Sharing: When insurers or others access data via the smart contract, they ideally receive the minimal information needed. For instance, instead of the insurer getting all raw heart rate readings, the platform might only share “average resting heart rate = 70, variance = X” or just the final risk score. This principle of data minimization means even after purchase, the user’s privacy is considered. The smart contract mechanism can enforce that only certain types of data are shared (which could be coded as part of the token/NFT metadata or by tying each contract function to a specific type of dataset or analysis result).
- Auditability: The use of blockchain provides an immutable audit log of data access. Any access of personal data is recorded as an event that the user can later review. This discourages misuse by data consumers because all transactions are public (or at least visible to the user and regulators). It also gives users assurance and insight into how often their data is accessed and by whom.
- Platform Security: Beyond data-specific privacy, we secure the platform’s infrastructure – e.g., ensuring the OCR and translation service, which handles sensitive text, is running in a secure sandbox and doesn’t log content; the twin database has strict authentication (only the user or their devices can retrieve identifiable data); the FL server cannot be easily tampered with to produce malicious models (and clients verify the server’s authenticity to avoid model poisoning).
- Privacy of the LLM Agent: When using GPT-4 to translate code, we are cautious not to expose private data. We only send model code (which isn’t personal data) to the LLM. We do not send any user-specific data to GPT. This ensures we are not leaking information via the LLM API. The worst-case if the LLM output is incorrect is just a bug in code, not a privacy breach.
By combining these measures, the system aims to comply with privacy principles like GDPR’s data protection by design. Users maintain control: they can refuse certain data to be collected (then the twin might be less complete, but that’s their choice), they can opt out of federated learning (then their device simply won’t join FL rounds), and they choose whether to monetize data. Even if they do monetize, they can specify what level of detail is shared. The architecture demonstrates that advanced analytics (like training predictive models) and data monetization can be achieved without violating privacy, using modern PETs.
Examples of Smart Contract Logic for Data Access
To clarify how the smart contract governs data access and payments, here are a few key scenarios encoded in the contract, with simplified logic:
User Registration: When a user registers their data:
| function registerData(uint quality, uint basePrice) public { require(quality <= 100); require(basePrice > 0); catalog[msg.sender] = DataInfo(msg.sender, basePrice, quality, 0); emit DataRegistered(msg.sender, quality, basePrice); } |
- This function can only be called by the user themselves (because it uses msg.sender as the key). It creates a DataInfo struct for the user, initializing accessCount to 0. The emit DataRegistered event logs the listing. For example, John calls this and the event might read: DataRegistered(user=0xABC…, quality=90, basePrice=10000000000000000).
Dynamic Pricing Rule (conceptual, not fully shown in code above): Suppose we want to charge 20% more for data with quality > 80, and also increase price by 10% every 5 accesses as a way to account for popularity.
We could implement in buyData:
| uint price = info.basePrice; if(info.quality > 80) { price = (price * 120) / 100; // +20% } if(info.accessCount >= 5) { // increase 10% for each block of 5 accesses uint blocks = info.accessCount / 5; price = price + (price * 10 * blocks) / 100; } require(msg.value >= price, “Insufficient payment”); |
This way, if John’s quality is 90, basePrice 0.01 ETH becomes 0.012 ETH for the first 5 sales. After 5 sales, it bumps by another 10%, etc. Such rules ensure compensation for high-quality or heavily-used data.
- Purchase Access: Already shown in the pseudocode, but to reiterate the key steps in plain language:
- Buyer calls buyData(user) with payment.
- Contract checks that the data is indeed registered by that user.
- Contract calculates the required price (considering any dynamic rules).
- If payment is sufficient, it transfers funds. In Solidity, using call to transfer allows arbitrary gas, which is fine here as no complex logic after transfer. We subtract a small platform fee – this incentivizes the platform operator to maintain the marketplace (could also be 0 in a purely peer-to-peer marketplace).
- Increments the accessCount. This is on-chain persistent storage.
- Emits DataPurchased(user, buyer, price, newAccessCount) event.
Off-chain Delivery Trigger: The DataPurchased event doesn’t deliver data by itself. Off-chain, our backend listening sees:
| { “event”: “DataPurchased”, “args”: { “user”: “0xABC…123”, “buyer”: “0xDEF…456”, “price”: “10000000000000000”, “newAccessCount”: “1” } } |
Our backend recognizes user = John (maybe we maintain a mapping of user addresses to our internal user IDs securely) and buyer = ACME Insurance (if we whitelisted their address as known buyer). It then prepares the data payload. We might have a predefined format or API call. For instance, the insurer’s systems might expose a URL to POST the data to once payment is confirmed. The backend could do:
data = assemble_data_for_user(user_id=John, detail_level=”basic_stats”)
requests.post(insurer_callback_url, json=data, headers={“X-Auth”: insurerAuthToken})
- The assemble_data_for_user would fetch John’s twin (or relevant parts, maybe only those allowed by John’s consent settings). Perhaps John indicated he allows sharing of step counts and risk scores but not raw heart rate variability. So the assembly respects that. In our demo, we might simplify by just printing the data to console or writing to a file like delivered_user1_to_insurer.json.
Royalty Distribution (if NFT resale): In a more complex scenario with NFTs, suppose the insurer could resell the data to a research firm. If John’s data was an NFT, John could get a royalty on secondary sales.
The contract snippet for that could look like:
| // inside a function handling transfer of NFT representing data uint royalty = (salePrice * royaltyPercent) / 100; payable(originalOwner).transfer(royalty); |
- Our referenced paper implemented two contracts, one to handle primary sale and one for royalty distribution on each transfer ( A Decentralized Marketplace for Patient-Generated Health Data: Design Science Approach – PMC ). For brevity, we won’t fully implement that here, but it’s an option to ensure users keep benefiting if their data asset changes hands multiple times.
User Withdrawal or Opt-Out: We should allow users to delist their data. A simple function:
| function unregisterData() public { delete catalog[msg.sender]; // Optionally emit event or mark as inactive } |
- If John no longer wants to sell data, he calls unregisterData. The contract removes his entry. Any future buyData(John) calls would fail the require(info.owner != address(0)). (In a real scenario, one might want a more nuanced approach: existing subscriptions might be honored until expiry, etc.)
Access Limits: Perhaps a user only wants to sell data up to 10 times or only to certain approved buyers. We could incorporate that by adding fields in DataInfo like maxAccess or an approvedBuyers list. The contract then would check accessCount < maxAccess or buyer in approvedBuyers.
Implementation:
| function registerData(uint quality, uint basePrice, uint maxAccess, address[] memory allowedBuyers) public { … } function buyData(address user) public payable { DataInfo storage info = catalog[user]; if(info.maxAccess > 0) { require(info.accessCount < info.maxAccess, “Access limit reached”); } if(info.allowedBuyers.length > 0) { bool allowed = false; for(uint i=0;i<info.allowedBuyers.length;i++) { if(info.allowedBuyers[i] == msg.sender) { allowed = true; break; } } require(allowed, “Buyer not approved”); } … } |
- This increases complexity and cost (loop in chain is not ideal), but it could be done or enforced off-chain by simply not advertising the data listing to non-approved buyers.
Through these examples, we see the smart contract acts as a governance and transaction layer, while heavy data transfer and enforcement of complex rules can often remain off-chain to save blockchain gas and maintain privacy (we don’t want to put the allowedBuyers list publicly on chain if it includes identifying info; better to have something like the contract requiring a cryptographic token from buyer that proves the user allowed them, akin to a voucher). However, the above logic is sufficient for a functional prototype on a private Ethereum instance.
Conclusion
This comprehensive prototype demonstrates that it is feasible to create a privacy-preserving mental health digital twin platform by combining federated learning, multi-modal data integration, AI-assisted deployment, and blockchain-based data rights management. We showed how personal health data from smartphones and clinical records can feed into a digital twin that is continuously updated and analyzed without compromising privacy: federated learning allows collaborative model training across iPhones, hospitals, and others without sharing raw data, enhanced by secure aggregation and differential privacy to protect individual contributions. The resulting models empower on-device intelligence – e.g., predicting mental health risks in real time – with an LLM agent streamlining the translation of models into deployable mobile code. Furthermore, the introduction of a smart contract data marketplace gives individuals agency to monetize their data safely, with cryptographic guarantees of payment and usage tracking on an immutable ledger ( A Decentralized Marketplace for Patient-Generated Health Data: Design Science Approach – PMC ). Insurers and researchers can access valuable insights (like risk scores or aggregated metrics) by paying users, but they do so under the user’s terms and with only the necessary information shared.
The system architecture (Figure 1) and the sequence of modules we detailed highlight a modular, scalable design: one can update the ML model architecture, swap in a different OCR engine, or deploy on a different blockchain network with minimal changes to other components. Real-world toolkits and libraries (Flower, PyTorch Lightning, HealthKit, Tesseract, FHIR, Solidity) are used to ensure that each piece is implementable with current technology.
While our prototype operates on a small scale (a few simulated clients and one insurer), it lays the groundwork for a full production system. In production, one would enhance reliability (e.g., handle dropped devices in FL), security (harden the OCR service, use enclave for FL aggregation perhaps), and compliance (ensure the whole pipeline meets regulations like HIPAA/GDPR – which our privacy-by-design approach facilitates). One could also extend functionality: e.g., use more advanced NLP on doctor’s notes to feed sentiment scores into the twin, or incorporate IoT data like sleep tracking. The federated approach can scale to hundreds or thousands of iPhones (Flower and TFF are designed for that), and the smart contract can be adapted to Layer-2 or permissioned chains if needed for throughput and privacy.
In conclusion, this prototype provides a technically detailed blueprint for a future where individuals have a rich digital twin of their mental health that aids in personal and clinical decision-making, where AI models learn from everyone’s data without exposing anyone’s privacy, and where users are rewarded for the use of their data in research or insurance underwriting, all through transparent and fair mechanisms. By following the design and code presented, developers can build and experiment with such a platform today, taking an important step toward more personalized, data-driven, and privacy-conscious mental health care.